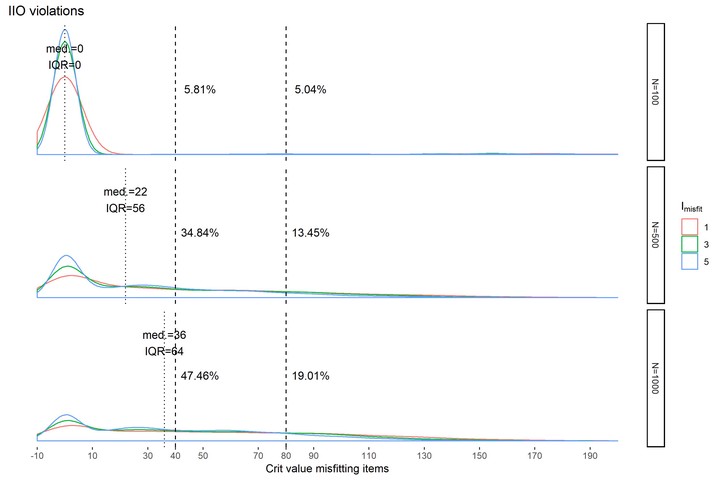
The Crit Coefficient in Mokken Scale Analysis: A Simulation Study and an Application in Quality-of-Life Research Daniela R. Crisan, Jorge N. Tendeiro, Rob R. Meijer January 2022 PDF Cite Code Preprint