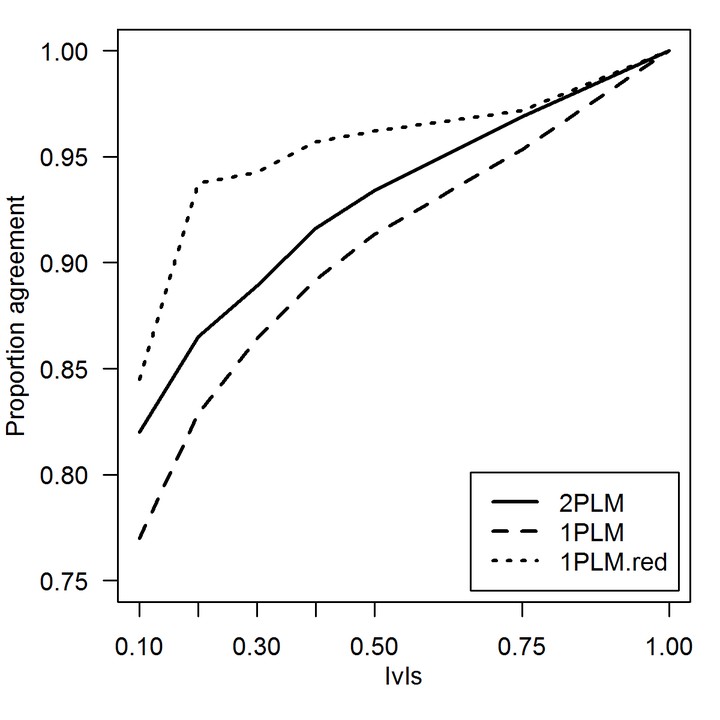
The effect of item and person misfit on selection decisions: An empirical study Rob R. Meijer, Jorge N. Tendeiro January 2015 Cite Source Document